Hoppe writes following as reply to Luskin:
Co-option and modification of existing structures is a ubiquitous phenomenon in evolution at levels ranging from molecular mechanisms to high-level structures like wings.
this is a confortable way to avoid the relevant questions, and Hoppe keeps avoiding them despite Luskin pointed out that its not only about modification and co-option of existing parts, but how de-novo genes evolved to start the make of new features. How did new structures and new kind of cells begin to evolve ?
Biological structures are well organized , structured, and build up like human made factories and machines. The process takes place fully automated inside the cell. The process of protein production ,starting from the genes, is extremely complex, and several steps are required. Bruce Alberts writes in
"The Cell as a Collection of Protein Machines: Preparing the Next Generation of Molecular Biologists," 9 :
But, as it turns out, we can walk and we can talk because the chemistry that makes life possible is much more elaborate and sophisticated than anything we had ever considered. We now know that nearly every major process in a cell is carried out by assemblies of 10 or more protein molecules. And, as it carries out its biological functions, each of these protein assemblies interacts with several other large complexes of proteins. Indeed, the entire cell can be viewed as a factory that contains an
elaborate network of interlocking assembly lines, each of which is composed of a set of large protein machines.
Ordered Movements Drive Protein Machines
Why do we call the large protein assemblies that underlie cell function protein machines? Precisely because, like the machines invented by humans to deal efficiently with the macroscopic world, these protein assemblies contain highly coordinated moving parts. Within each protein assembly, intermolecular collisions are not only restricted to a small set of possibilities, but reaction C depends on reaction B, which in turn depends on reaction A—just as it would in a machine of our common experience.
Underlying this highly organized activity are ordered conformational changes in one or more proteins driven by nucleoside triphosphate hydrolysis (or by other sources of energy, such as an ion gradient).the nearly ubiquitous use of energy-driven conformational changes to promote the local assembly of protein complexes, thereby creating a high degree of order in the cell, has become universally recognized.
We have also come to realize that protein assemblies can be enormously complex. Consider for example the spliceosome. Composed of 5 small nuclear RNAs (snRNAs) and more than 50 proteins, this machine is thought to catalyze an ordered sequence of more than 10 RNA rearrangements as it removes an intron from an RNA transcript. As cogently described in this issue of Cell by Staley and Guthrie (1998), these steps involve at least eight RNA-dependent ATPase proteins and one GTPase, each of which is presumed to drive an ordered conformational change in the spliceosome and/or in its bound RNA molecule. As the example of the spliceosome should make clear, the cartoons thus far used to
depict protein machines vastly underestimate the sophistication of many of these remarkable devices.
Many different types of chemical reactions are required to produce a properly folded protein from the information contained in a gene 1)
The journey from gene to protein is complex and tightly controlled within each cell. It consists of two major steps: transcription and translation. Together, transcription and translation are known as gene expression.
4
The cell sends activator proteins to the site of the gene that needs to be switched on, which then jump-starts the RNA polymerase machine by removing a plug which blocks the DNA's entrance to the machine. The DNA strands do shift position so that the DNA lines up with the entrance to the RNA polymerase. Once these two movements have occurred and the DNA strands are in position, the RNA polymerase machine gets to work melting them out, so that the information they contain can be processed to produce mRNA
2 The process follows then after INITIATION OF TRANSCRIPTION through RNA polymerase enzyme complexes, the mRNA is capped through Post-transcriptional modifications by several different enzymes , ELONGATION provides the main transcription process from DNA to mRNA, furthermore SPLICING and CLEAVAGE ,
polyadenylation where a long string of repeated adenosine nucleotides is added, AND TERMINATION through over a dozen different enzymes, EXPORT FROM THE NUCLEUS TO THE CYTOSOL ( must be actively transported through the Nuclear Pore Complex channel in a controlled process that is selective and energy dependent
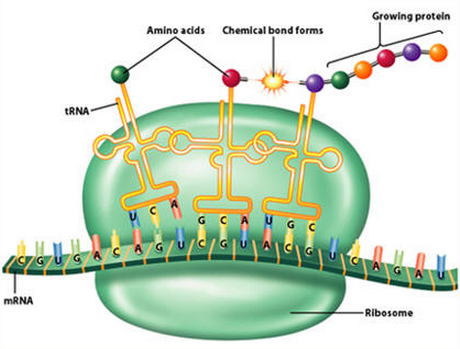
3 ) INITIATION OF PROTEIN SYNTHESIS (TRANSLATION) in the Ribosome in a enormously complex process, COMPLETION OF PROTEIN SYNTHESIS AND PROTEIN FOLDING through chaperone enzymes. From there the proteins are transported by specialized proteins to the end destination. Most of these processes require ATP, the energy fuel inside the cell.

Each of these steps requires extremely complex proteins and enzymes, the working horses of the cell, which work like robots in a assembly line in highly regulated precise steps, and these machines are by themself encoded in the genome. Not only is the information to make them stored in the genome. But these machines require further , different proteins and enzymes in order to be prepared and assembled. And the information for these processes taking place is also recorded in the genome. And a few genes contain the information to produce molecules that help the cell assemble proteins, that is, the build up of the whole machinery must also be pre-programmed, and happen in a sequencial special, ordered manner. Many different processes need to happen at the same time, driven by ATP, which means, the ATPase powerhouse and proton gradient and membranes must be extant since the beginning. In the same way, that we build a machine, each part must be mounted at the right place, at the right time, in the right sequence and order, and the parts must fit together in a functional and precise way. And the right materials are needed. In a car engine, the pistons must be made by the right temperature resistant metals, and so it is also inside the cells. Most enzymes have reaction centers , where special substrates and reacton factors are required to exercise their specific reactions, and many enzymes require the presence of other compounds - cofactors - before their catalytic activity can be exerted.
5 How could natural mechnisms " figure out " what special materials, like metal-ion-activators, are required to produce given reaction ? Trial and error ? Furthermore, following is required:
C1: Availability. Among the parts available for recruitment to form a biological system consisting of multiple parts, there would need to be ones capable of performing the highly specialized tasks of the specific system, even though all of the items serve some other function or no function in another system where they were recruited from.
C2: Synchronization. The availability of these parts would have to be synchronized so that at some point, either individually or in combination, they are all available at the same time.
C3: Localization. The selected parts must all be made available at the same ‘construction site,’ perhaps not simultaneously but certainly at the time they are needed.
C4: Coordination.The parts must be mutually compatible, that is, ‘well-matched’ and capable of properly ‘interacting’: even if the subunits are put together in the right order, they also need to interface correctly. The parts must be coordinated in just the right way: even if all of the parts of a ribosome are available at the right time, it is clear that the majority of ways of assembling them will be non-functional or irrelevant.
C5: Interface compatibility. The parts must be mutually compatible, that is, ‘well-matched’ and capable of properly ‘interacting’: even if the subunits are put together in the right order, they also need to interface correctly.
So these further questions arise :
For what reason would natural processes produce the machines like for example
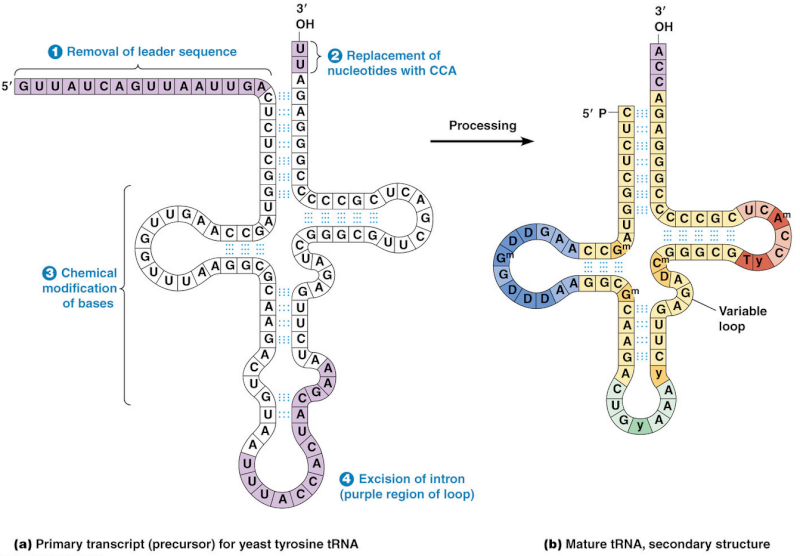
Ribonuclease P, which processes pre-tRNA, which contains additional tRNA sequences at both the 5’ and 3’-ends and need to be removed ? For what reason would natural processes produce tRNA which are required inside the Ribosome , the central molecule in the translation process ? ( lets mention that the very own factories that are made through them, make these enzymes and proteins..... Catch 22..... )
P Ribonuclease P would have no function by its own. tRNA has no function by its own. The Ribosome has no function by its own. These individual parts exercise only their function, if interlocked and working in a interdependent way together. Supposing everything would start through natural processes, how could these machines arise separately, in a stepwise fashion, if they do not have any use by their own ? Its not that we can argue that we simply don't know yet. What we do know, permits us rationally to infer, that naturalistic explanations are entirely inadequate to explain the phenomena in question. A initial blueprint is required, where the whole process is pre-programmed, which is the case in the genome, where all the information to build a cell is stored, and the whole process has to start all at once. That seems to be best explained through a intelligent designer.
Mark Perakh then goes on in another article, published in
The Panda's thumb, and writes :
Dembski’s new definition of IC means in fact “the death” of IC because it adds an impossible condition for a system to be recognized as IC. This condition does in fact require proving a universal negative: to be IC, the system, according to Dembski’s new definition, must be such that its function cannot be performed by any other simpler system. With this requirement no system can ever be asserted to be IC because it is impossible to assert that there is no other, simpler system anywhere in any form that can perform the job, even at a lower level of fitness. If we can’t point to such a simpler system, it does not mean it cannot exist; the possibility that such a system exists but we simply don’t know about it can never be excluded.
Well, thats a evident strawman argument. We know that DNA cannot exercise its function, unless 3 essential parts, namely the bases, the phosphate backbone, and the deoxyribose sugar are in place. Take any one of the 3 parts away, bye bye functionality. Take away 3 of the 4 bases, bye bye with the genome's language. Take away the energy of the cell, ATP, and almost all action would cease. The list could go on and on. So, i think the exposed facts here give further reason to infer design as the most adequate, capable, potent, precise and correct explanation for what we observe in the natural world, and specially inside the cell.
As
uncommondescent 10 puts it:
ID is not proposing “God” to paper over a gap in current scientific explanation. Instead ID theorists start from empirically observed, reliable, known facts and generally accepted principles of scientific reasoning: